
In March, OpenAI released GPT-4, a large language model that was remarkably skilled at identifying prime numbers. It accurately labeled 97. 6 percent of a series of 500 prime numbers provided to it. However, the model's performance took a drastic turn in June. During the same test, GPT-4 only correctly labeled 2. 4 percent of the prime numbers. This change emphasizes the complexity of large AI models, which do not consistently improve in every task. Instead, their progress resembles a winding road with obstacles and diversions. The dramatic shift in GPT-4's performance was detailed in a preprint study conducted by three computer scientists: two from Stanford University and one from the University of California, Berkeley. The researchers compared GPT-4 to its predecessor, GPT-3. 5, in tests conducted in March and June, revealing numerous differences between the two models and variations in their output over time. Notably, in June, GPT-4's responses were less verbose compared to March, and the model appeared less inclined to provide explanations. It also acquired new quirks, such as appending accurate but potentially disruptive descriptions to sections of computer code. On the positive side, GPT-4 became more cautious, filtering out more offensive responses and displaying a reduced inclination to offer illegal or discriminatory suggestions. It also showed a slight improvement in solving visual reasoning problems. The study, which is not yet peer-reviewed, led some AI enthusiasts to perceive GPT-4 as less effective than its predecessor, leading to headlines questioning whether GPT-4 was "getting dumber. " However, this oversimplifies the reality of generative AI models, according to James Zou, one of the study's co-authors and an assistant professor of data science at Stanford University. Zou explains that it is challenging to determine whether GPT-4 or GPT-3. 5 is getting better or worse overall because the notion of improvement is subjective. OpenAI claims that, based on its internal metrics, GPT-4 performs better than previous versions across a range of tests. However, the company does not release benchmark data for every update, and they declined to comment on the recent preprint study.
OpenAI's reluctance to discuss the development and training of its large language models, as well as the opaqueness of AI algorithms, make it difficult to understand the causes behind changes in GPT-4's performance. Speculation and extrapolation are the only options for researchers outside the company. It is evident that GPT-4's behavior has changed since its initial release, as acknowledged by OpenAI in a blog post update. This behavioral shift, known as "model drift, " has been observed in the past with other models. This presents a challenge for developers and researchers who rely on these AI models for their work, as their expectations and usage could be disrupted when the model's behavior changes unexpectedly. Fine-tuning is a common process used to adjust AI models after initial training, and it can have unintended consequences. The capability and behavior of an AI are shaped by the model's parameters and the training data. Modifying parameters can unexpectedly alter the AI's behavior, and fine-tuning, akin to gene editing, introduces mutations that can result in ripple effects. Researchers like Zou are exploring ways to make the adjustment of big AI models more precise to avoid undesirable effects. In the case of GPT-4, changes made by OpenAI may have been aimed at reducing offensive or dangerous outputs but inadvertently impacted other aspects of the model's performance. For example, new limits on what the model can say may have unintentionally reduced its ability to provide detailed answers regarding prime numbers. Alternatively, the fine-tuning process might have introduced lower-quality training data that affected the level of detail in GPT-4's responses about certain mathematical topics. Regardless of the specific causes, it seems likely that GPT-4's actual ability to identify prime numbers did not change significantly between March and June. The model might have been relying more on trends in the data it was exposed to, leading to a shift in its default answer based on incidental patterns rather than actual reasoning. However, it's important to note that AI models do not develop habits like humans because they lack independent understanding and context. They rely solely on data to mimic reasoning rather than possessing true reasoning abilities.
None




IBM has announced a major acquisition of Confluent, proposing $31 per share, which represents a 34% premium over the previous trading day's closing price.

**The Silent Shift: How LLM Perception Drift Is Set to Transform SEO Metrics by 2026** In digital marketing’s rapidly changing landscape, a novel metric—LLM perception drift—is emerging as a potential revolution for SEO strategies

Dec 3 (Reuters) - On Wednesday, Microsoft denied a report from The Information claiming that multiple divisions within the company reduced sales growth targets for certain artificial intelligence products after several sales staff failed to meet their goals in the fiscal year ending June.

HeyGen, a leading innovator in artificial intelligence technology, has launched its new National News Video Maker, an advanced platform poised to transform the production of national news videos and breaking news segments.

TwinTone is transforming influencer marketing and social commerce through its AI-powered creator twins platform, enabling brands to instantly scale content production and engagement.

Anthropic, a prominent artificial intelligence company, has announced that it currently has no immediate plans to pursue an initial public offering (IPO).
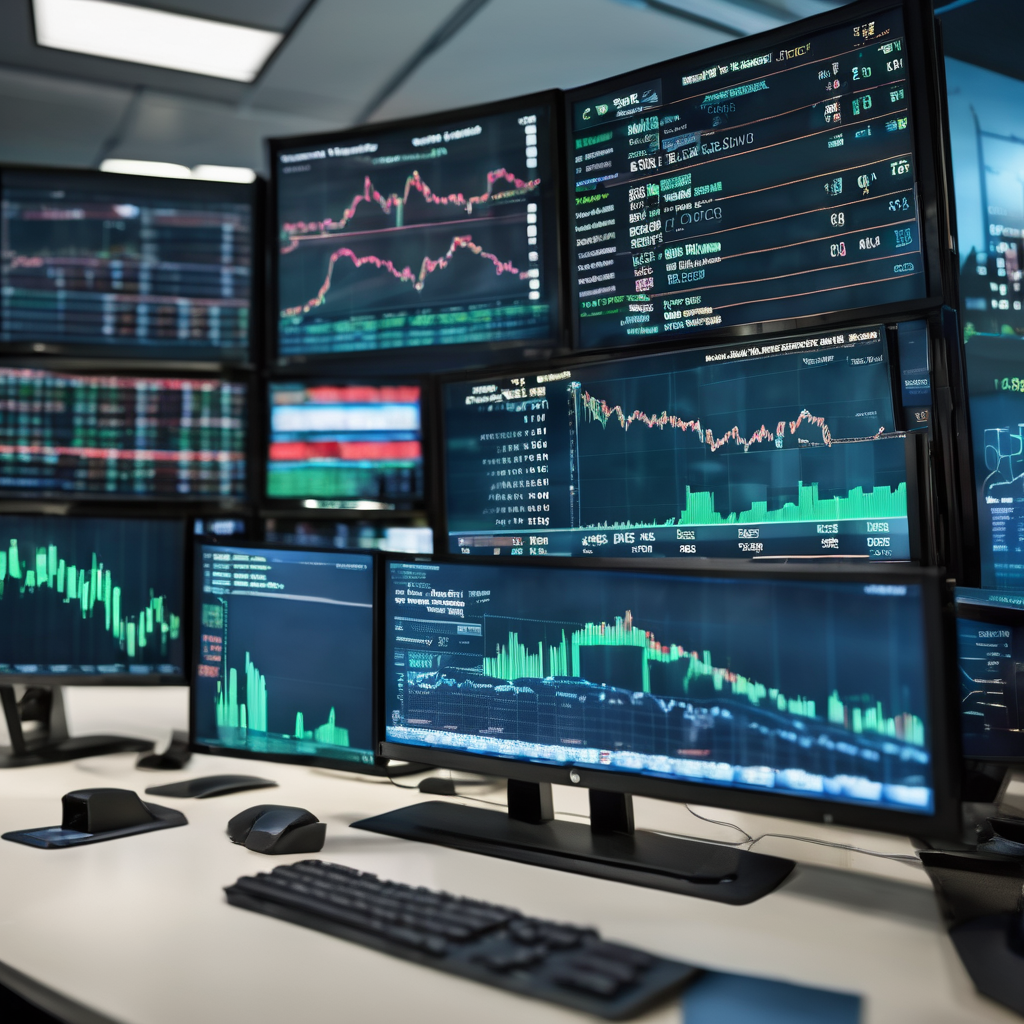
On Wednesday, Microsoft disputed a report claiming the company had lowered growth targets for its artificial intelligence software sales after many salespeople failed to meet those goals in the previous fiscal year.
Launch your AI-powered team to automate Marketing, Sales & Growth

and get clients on autopilot — from social media and search engines. No ads needed
Begin getting your first leads today

Lorem ipsum dolor sit amet consectetur adipisicing elit. Fuga dolor minus maiores. Aut vero expedita dicta, dolorem odit excepturi odio doloremque voluptatem repellat aliquam? Dolores nemo eum id pariatur! Nobis!

Create your own avatar to work for you — completely free of charge!
Sign up with
We've sent a confirmation email to
Please check your inbox and click the link to complete your registration
Didn’t receive it? Check your Spam or Promotions folder
and get clients without any advertising investment!

Create and publish viral social media content on autopilot

AI sales managers work 24/7, with no need for sleep, food, or breaks, and speak all languages.
You have unsubscribed from the mailing list recklessly but successfully.
We are not saying goodbye and look forward to seeing you again.